In this post, I will talk about L2 architecture in Linux kernel network stack, focus on data flow, how packets receiving in, and route out. About network topology maintaining, like STP, I won’t talk here.
how packets receiving in ?
Hardware interrupt will raise when packets arrive, hardware driver deliver packets to CPU input queue via netif_rx, which define in file net/core/dev.c, and then, raise Softirq NET_RX_SOFTIRQ, and packets are received into layer 2 in Softirq handler, check the initialize part:
static int __init net_dev_init(void)
{
...
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
...
}
net_rx_action is used to receive packets from CPU input queue, it will call netif_receive_skb, then __netif_receive_skb_core, which is the main function to route packets, let’s check this function in detail:
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
ptype_all is used for delivering packet from kernel to user space directly, bypassing L2, and L3 firewall system, but it just copy packets into user space, and don’t stop here, the original packets processing continue. Packets capturing tools, like wireshark, sniffer, use this to capture all packets, and we can register HOOK at ptype_all list to receive specific kind of packets via creating L2 socket.
if (vlan_tx_tag_present(skb)) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto unlock;
}
VLAN process here, if receiving interface is in bridge, it won’t reach here, because packets already route out in bridge with VLAN header, code here is for packets reaching local host, it takes off VLAN header before delivering up.
type = skb->protocol;
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
if (pt_prev) {
if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))
goto drop;
else
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
ptype_base is receiving HOOK list of L3 protocol, when network layer init, all supported protocol will register on this list, like IPV4, IPV6, when L3 protocol find on this list, packets will deliver into layer 3, or it will be dropped, code will reach here when receiving interface is not in bridge, or packets’s target MAC is local host, which will go into bridge stack first, and then route back.
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto unlock;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
case RX_HANDLER_PASS:
break;
default:
BUG();
}
}
rx_handler is the entry point to deliver packet into bridge stack, check br_add_if in file net/bridge/br_if.c, we can see when network interface add into bridge, its rx_handler will assign to br_handle_frame.
int br_add_if(struct net_bridge *br, struct net_device *dev)
{
...
err = netdev_rx_handler_register(dev, br_handle_frame, p);
if (err)
goto err5;
...
}
It may have some differences from version to version in Linux kernel, like delivering packets optimization from physical layer to data link layer, its optimizing direction is minimize the frequency of IRQ, but the main steps always the same, the code I show here is kernel version 3.13.
Bridge Stack
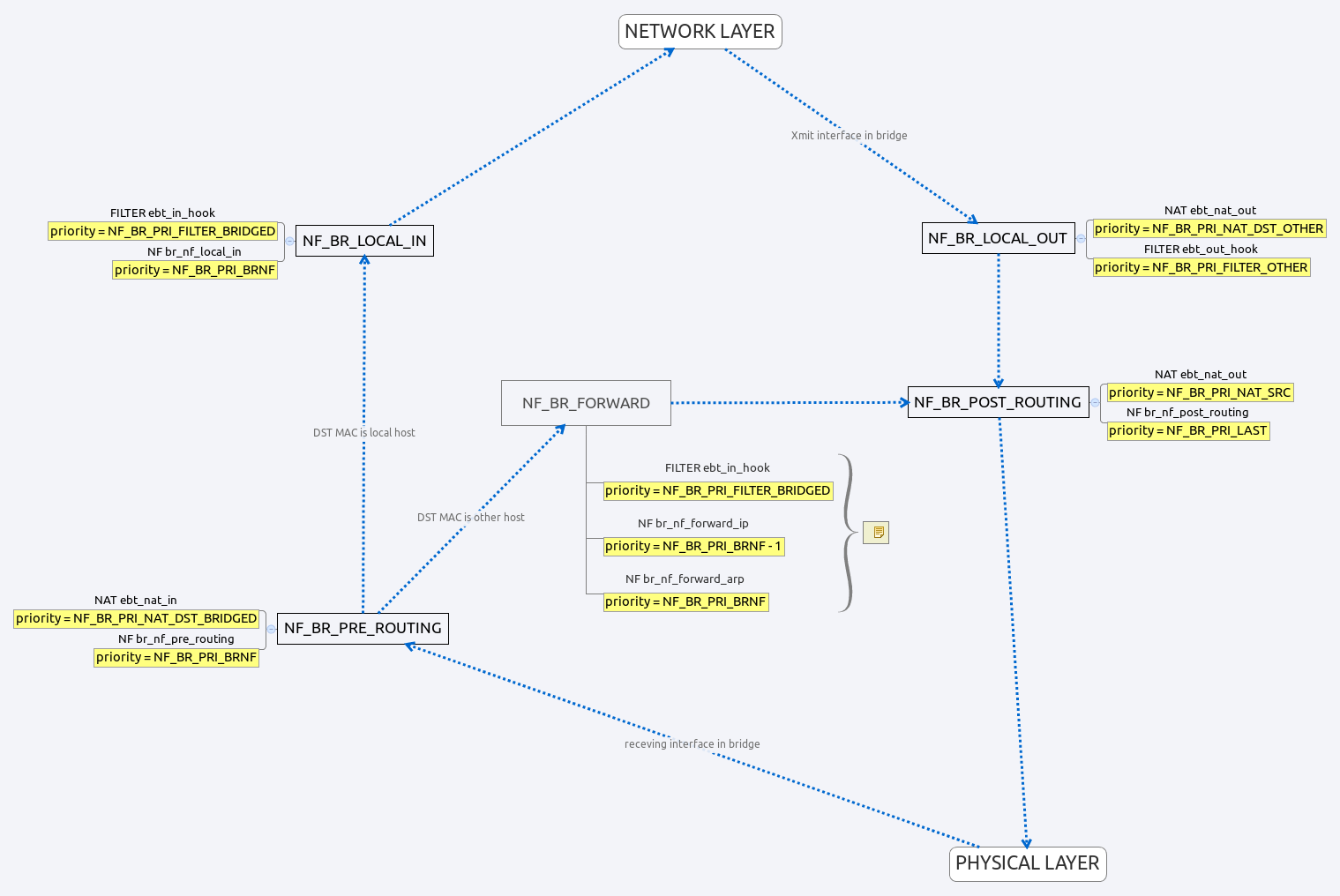
as we can see from figure above, when packets enter into bridge stack via br_handle_frame, the first HOOK it need to go through is NF_BR_PRE_ROUTING, there are many hook operations linked on every HOOK, and every hook operation has its priority.
First, let’s check this priority structure, it is a enumerate, define in file include/linux/netfilter_bridge.h:
enum nf_br_hook_priorities {
NF_BR_PRI_FIRST = INT_MIN,
NF_BR_PRI_NAT_DST_BRIDGED = -300,
NF_BR_PRI_FILTER_BRIDGED = -200,
NF_BR_PRI_BRNF = 0,
NF_BR_PRI_NAT_DST_OTHER = 100,
NF_BR_PRI_FILTER_OTHER = 200,
NF_BR_PRI_NAT_SRC = 300,
NF_BR_PRI_LAST = INT_MAX,
};
Hook operations with priority value NF_BR_PRI_FIRST have the highest priority, they will be executed before other rules, the implementation is simple, it is just a list, hook operations with low value are inserted toward head, and high value are inserted toward tail, and what about hook operations with the same priority ?
int nf_register_hook(struct nf_hook_ops *reg)
{
struct nf_hook_ops *elem;
int err;
err = mutex_lock_interruptible(&nf_hook_mutex);
if (err < 0)
return err;
list_for_each_entry(elem, &nf_hooks[reg->pf][reg->hooknum], list) {
if (reg->priority < elem->priority)
break;
}
list_add_rcu(®->list, elem->list.prev);
mutex_unlock(&nf_hook_mutex);
#if defined(CONFIG_JUMP_LABEL)
static_key_slow_inc(&nf_hooks_needed[reg->pf][reg->hooknum]);
#endif
return 0;
}
From code above, it is not difficult to see that hook operation inserted later will be executed first in the hook operations with the same priority.
Every hook operation has a hook function attached, when it get reached on list, its hook function will be executed.
struct nf_hook_ops {
struct list_head list;
/* User fills in from here down. */
nf_hookfn *hook;
struct module *owner;
void *priv;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
Let’s look at one example:
static struct nf_hook_ops ebt_ops_filter[] __read_mostly = {
{
.hook = ebt_in_hook,
.owner = THIS_MODULE,
.pf = NFPROTO_BRIDGE,
.hooknum = NF_BR_LOCAL_IN,
.priority = NF_BR_PRI_FILTER_BRIDGED,
},
{
.hook = ebt_in_hook,
.owner = THIS_MODULE,
.pf = NFPROTO_BRIDGE,
.hooknum = NF_BR_FORWARD,
.priority = NF_BR_PRI_FILTER_BRIDGED,
},
{
.hook = ebt_out_hook,
.owner = THIS_MODULE,
.pf = NFPROTO_BRIDGE,
.hooknum = NF_BR_LOCAL_OUT,
.priority = NF_BR_PRI_FILTER_OTHER,
},
};
This is the filter system in bridge stack, it consists of three hook operations, which registered on NF_BR_LOCAL_IN, NF_BR_FORWARD, and NF_BR_LOCAL_OUT, each hook operation has a hook function, we can add filter rules via command ebtables, in kernel, it just link that rule into filter rule list, when filter hook operation get reached on each HOOK, hook function, such as ebt_in_hook, and ebt_out_hook, will iterate filter rule list, and each rule in filter rule list of that HOOK will be applied.
Ok, let’s jump into the framework of bridge stack
HOOK NF_BR_PRE_ROUTING
there are two hook operations registered on this HOOK, one with priority NF_BR_PRI_NAT_DST_BRIDGED, one with priority NF_BR_PRI_BRNF.
The first hook operation is used for DNAT, it means we can change packets destination information, like destination MAC address, which we can add rules at NAT table via ebtables.
The second hook operation will do some destination fix up if DNAT takes place, re-parse layer 3 header, and route packet.
HOOK NF_BR_FORWARD
there are three hook operations registered on this HOOK, one with priority NF_BR_PRI_FILTER_BRIDGED, one with priority NF_BR_PRI_BRNF-1, and one with priority NF_BR_PRI_BRNF.
The first hook operation with hook function ebt_in_hook will iterate filter rules registered on this HOOK, and return when one rule match.
The second hook operation with hook function br_nf_forward_ip, as the name imply, it used to forward IP packets, how? it let packet go through all hook operations registered on HOOK NF_INET_FORWARD at layer 3, if not IP packets, it just let it pass through.
The third hook operation with hook function br_nf_forward_arp, it used to deal with ARP packet, packet will deliver to HOOK NF_ARP_FORWARD. For ARP, its framework consists of three HOOK, which are NF_ARP_IN, NF_ARP_OUT, and NF_ARP_FORWARD, details can be seen in file net/ipv4/arp.c.
HOOK NF_BR_LOCAL_IN
There are two hook operations registered on this HOOK, one with priority NF_BR_PRI_FILTER_BRIDGED, and one with priority NF_BR_PRI_BRNF.
The first hook operation with hook function ebt_in_hook, as mentioned above, it used for packet filtering.
The second hook operation with hook function br_nf_local_in will do some destination checking, packets will deliver up to layer 3 if destination is right, or packets will be drop.
HOOK NF_BR_LOCAL_OUT
There are two hook operations registered on this HOOK, one with priority NF_BR_PRI_NAT_DST_OTHER, one with priority NF_BR_PRI_FILTER_OTHER.
The first hook operation with hook function ebt_nat_out will iterate NAT rules registered on this HOOK, and return when one rule match.
The second hook operation with hook function ebt_out_hook will iterate filter rules registered on this hook, and return when one rule match.
HOOK NF_BR_POST_ROUTING
There are two hook operations registered on this HOOK, one with priority NF_BR_PRI_NAT_SRC, one with priority NF_BR_PRI_LAST.
The first hook operation with hook function ebt_nat_out, as mentioned above, it is used for NAT.
The second hook operation with hook function br_nf_post_routing will deliver packets to HOOK NF_INET_POST_ROUTING for IP, it will do some connection fix up if NAT takes place there, if not IP packets, it just pass it through.
how packet send out ?
After packets go through bridge stack, layer 2 header will be inserted into packets, and the API to send packets out is dev_queue_xmit, if QOS is enabled, packets will be enqueued, or it will be deliver into network device’s transmit queue directly, and interrupt NET_TX_SOFTIRQ raise, packets are delivered down.
conclusion
From the framework of bridge stack, we can see there are several hook operations registered on each HOOK, each hook operation has one priority, which determine its execution order. During our development, we can extend hook operations on each HOOK dynamically based on our needs, what we should take care about is their priority and what character each HOOK is in framework.
